Object Detection目标检测
Two Stage Objection Detection
RCNN
将物体检测当做分类问题处理,即先提取一系列的候选区域,然后对候选区域进行分类。Two-staged
- 候选区域生成:region proposal,此时用的是selective search算法:先将图片分割成小区域,然后再合并包含同一物体可能性高的区域并输出,提取2000个候选区域,并对每一个区域进行归一化处理得到固定大小的图像
- CNN特征提取。用CNN网络得到固定维度的特征输出。
- SVM分类器:使用线性分类器对输出的特征进行分类,并采用了难样本挖掘来平衡正负样本的不平衡
- 位置精修:通过一个回归器,对特征进行辩解回归以得到更为精确的目标区域
- 三个问题:
- 多步训练:步骤繁琐且训练速度较慢
- 分类需要用MLP网络,因此输入的尺寸固定
- region proposal需要提取并保存,占用空间较大
Fast RCNN
有三点改进:
- 共享卷积:整幅图送到卷积网络中进行区域生成来减少计算量,但依旧采用selective search方法。
- RoI Pooling:region of interesting,利用特征池化的方法进行特征尺度变换,可以处理任意大小的图片
- 多任务损失:将分类和回归网络放在一起训练,放弃SVM,采用softmax函数进行分类
Faster RCNN
采用Region Proposal Network,利用Anchor机制将区域生成和卷积网络联系在一起。Anchor可以看作是图像上很多固定大小和宽高的方框,FasterRCNN认为只需要将anchor和物体进行匹配,然后对anchor进行分类和位置的微调就可以完成检测,降低了网络收敛的难度
包括4个部分:
- 特征提取网络Backbone:输入图像经过Backbone得到feature map
RPN Module:区域生成模块,生成region proposal:
RPN in Stage One
- Anchor生成:RPN对feature map上的每一个点都对应了9个anchor。这9个anchor大小宽高不同,[8,16,32]x[0.5,1,2]。每个点的9个anchor对应原尺寸图片上的9个框。
- Anchor与标签的匹配。这些框映射回输入图片的尺寸,然后和ground truth中的bbox做IOU。对于每个Anchor和每个标签,判断标准如下(注意顺序不能随意变动):
- 对于任何一个Anchor,与所有标签的最大IoU小于0.3,视为负样本
- 对于任何一个Label,与其最大IoU的Anchor,视为正样本(保证每个标注的物体有bbox)
- 对于任何一个Anchor,与所有标签的最大IoU大于0.7,视为正样本
- 为了保证这一阶段的召回率Recall,允许一个标签对应多个anchors,而不允许一个anchor对应多个标签。正样本视为前景(有物体的区域),负样本视为背景(无关注物体的区域)
- Anchor的筛选:因为生成了2万个anchor,如果全部采用则正负样本不均衡,不利于网络收敛。RPN默认选择256个Anchors进行损失计算,其中最多不超过128个正样本。
求解回归偏移值:对于这些anchor,我们计算其与ground truth的偏移值
位置偏移$t_x$和$t_y$利用了宽高进行归一化,宽高偏移$t_w$和$t_h$进行了对数处理,限制了偏移量的范围,利于收敛。在后面预测值的时候,直接将预测的$x,y,w,h$替换上式中的gt,然后求真值 $t_x,t_y,t_w,t_h$ 和新得到的值的差值就可以进行学习。
- 通过这样的方式缩小了框的坐标变化幅度,只需要预测相对这个anchor的移动量,使得网络易于收敛,准确预测。anchor相当于给了一个强先验,说物体都在我给的这些框里。损失函数设计
其中 $\sum_i L_{cls}(P_i, P_i^)$是256个筛选出来的Anchors的分类损失,$P_i$是每个Anchor的类别gt,$P_i^$是每个Anchor的预测值,此处指判断是否是前景,不判断具体class,用cross entropy。
$\sum_i P_i^ L_{reg}(t_i, t_i^)$代表了回归损失,其中bbox_inside_weights实际上起到了$p_i^*$进行筛选的作用,bbox_outside_weights 起到了$\lambda\frac{1}{N_{reg}}$来平衡两部分损失的作用。
当预测值与gt差距太大时,采用L1 loss免得导数太大无法收敛。
RPN in Stage Two
- RPN的功能是region proposal。具体方式和训练RPN相同:
- backbones提取feature maps
- 过RPN网络得到(4x9xHxW)和(2x9xHxW)个值,
- 根据分类网络输出的得分(也就是后者)排序,取前12000个得分最高的anchors
- 通过Non-Maximum Suppression来将重叠的框去掉:
先将anchors按得分排序,取最大的得分的anchor保留,去除所有与这个anchor IoU超过一定threshold的anchors。然后再取剩下的中的最大得分的anchor,重复上一个步骤,直到原始的anchors集都用完。 - 取前2000个作为最后的proposal regions
- 2000个proposal region与所有的物体标签的IoU,根据IoU矩阵的值来筛选出符合条件的正负样本,筛选标准如下:
- 对于任何一个proposal,其与所有标签的最大IoU如果大于等于0.5,视为正样本
- 对于任何一个proposal,其与所有标签的最大IoU如果大于等于0且小于0.5,视为负样本
然后对于分类出来的正负样本,控制正负样本比例满足1:3,总数控制在256个。因此正样本数量不超过64个,超过就随机取64个。负样本取256-p个,超过也随机取256-p个。
这样做的目的是:
- 筛选出更贴近正式物体的RoI
- 减少送入后续全连接网络的数量,有效减少了计算量
- 完成了后续RCNN部分的真值计算
RoI Pooling层
RPN给出了256个proposal region以及对应的ground truth;Backbone给出了feature maps。因为proposal region是对于原图尺寸而言的,将RoI映射到feature上就是RoI Pooling。
假设当前RoI为332x332,backbone提取的feature maps下采样率为16,目标features为512x7x7。
- 将332x332下采样16倍,得到20.75x20.75并向下取整,得到20x20.
要将20x20的区域处理为7x7的特征。因为 $ 20/7 \approx 2.857$再次向下取整,采取2x2大小,stride=2的max pooling,得到7x7的输出。
- 以输入图片为参考坐标的候选框在feature maps上如何映射? 其中,f下标是feature map,i下标是image,$(X_f,Y_f)$位feature上的坐标点,$(X_i,Y_i)$为原始image上的坐标点。
- 如何把形状和大小各异的RoI归一化为固定大小的目标识别区域?
通过对feature map分块池化归一化到固定大小,即第二步,分成$(H_i/H_r)\times (W_i/W_r)$块,对每块MaxPool。
这里的问题是:因为两次向下取整,势必带来偏差,影响正确率。
An Alternative Way: RoI Align
取消量化操作,利用双线性插值Bilinear Interpolation的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转为一个连续的操作。
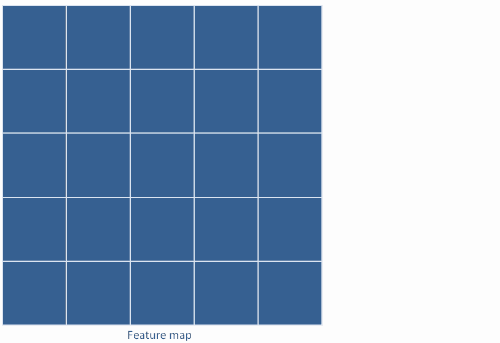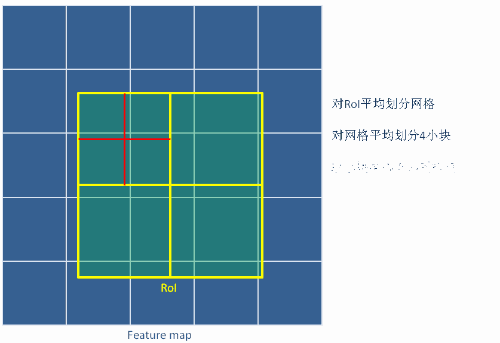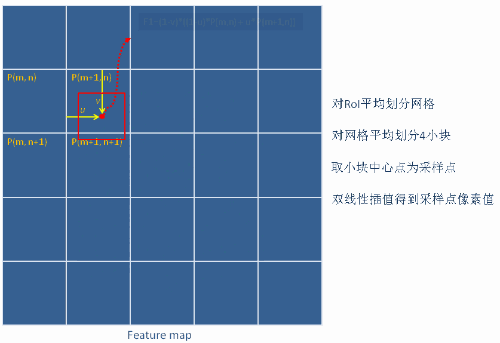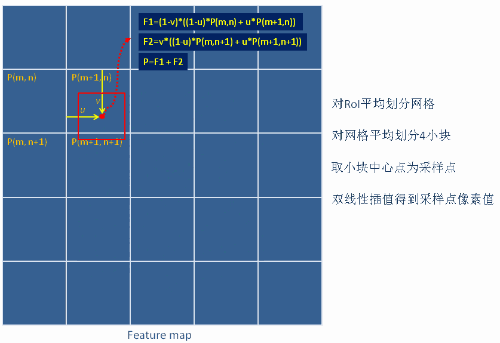
- 遍历每一个候选区域,保持浮点数边界不做取整。
- 将候选区域分割成kxk个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置(即:假定4个采样点),用双线性差值的方法计算出这四个位置的值,然后做最大池化操作。以下图为例,将RoI分割成2x2的单元格,再将每个单元格子划分成4个小方格,以每个小方格的中心作为采样点(红色点)对它进行 双线性插值,得到该采样点的像素值。最后对4个采样点max pooling得到最后ROI Align的结果。
设一个点$(x,y)$,知道四个点$Q_{11}=(x_1,y_1),Q_{12}=(x_1,y_2),Q_{21}=(x_2,y_1)$以及$Q_{22}=(x_2,y_2)$
先按x方向进行线性插值
$$f(x,y_1) = \frac{x_2-x}{x_2-x_1}f(Q_{11})+\frac{x-x_1}{x_2-x_1}f(Q_{21})\\
f(x,y_2) = \frac{x_2-x}{x_2-x_1}f(Q_{12})+\frac{x-x_1}{x_2-x_1}f(Q_{22})\\
$$
再按y方向进行线性插值
$$f(x,y) = \frac{y_2-y}{y_2-y_1}f(x,y_1) + \frac{y-y_1}{y_2-y_1}f(x,y2)$$

- ROI Align的反向传播
普通RoI Pooling反向传播公式为:
$$\frac{\partial L}{\partial x_i}= \sum_r\sum_j[i=i^*(r,j)]\frac{\partial L}{\partial y_{rj}}$$
其中x_i是池化前feature map上的像素点,y_rj代表池化后第r个候选区域的第j个点,i^*(r,j)代表y_rj像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)
RoI Align的反向传播需要做出修改:
$$\frac{\partial L}{\partial x_i}=\sum_r\sum_j[d(i,i^*(r,j)) < 1](1-\triangle h)(1-\triangle w)\frac{\partial L}{\partial y_{rj}}$$
因为$x_i^*(r,j)$是一个浮点数的坐标位置,在池化前的特征图中,每个与$x_i^*(r,j)$横纵坐标均小于1的点都应该接受与此对应的点$y_{rj}$回传的梯度,d(.)表示两个点之间的距离,$\triangle h$和$\triangle w$表示$x_i$和$x_i^*(r,j)$横纵坐标的差,这里作为双线性内插的系数乘在原始梯度上。
全连接RCNN
RoI Pooling得到256x512x7x7的features,将后面三维展开成1维,利用VGGNet的两个全连接层,得到256x4096的RoI特征。为了预测类别和回归,将4096维分别接入分类和回归的MLP中。分类网络输出num of class+1(background)维,回归网络输出每个类别下的4个位置偏移量。于是一共输出(num_of_cls+1)*4维。
- 虽然256个ROI放在了一起计算,但是相互之间独立,并没有共享特征,造成了重复计算。
损失函数与RPN类似,只不过此时分类softmax为21类不再是2类。回归时最多有64个正样本参与回归计算,负样本不参与回归计算。
- 一些缺点和后续改进:
- 卷积提取网络:对于多尺度和小尺寸的物体不友好,没有融合多层feature maps
- NMS:对于遮挡物体不友好,因为会直接删除掉造成漏检。
- RoI Pooling:两次向下取整带来feature上的影响,mask rcnn提出RoI Align
- RCNN全连接:没有权值共享
- 正负样本:需要超参来限制正负样本的数量
- 两个阶段:无法达到实时。
YOLO系列
YOLO v1
- 首先将输入图片resize到448x448大小,送入CNN网络,最后输出得到7x7的特征图。
- 特征提取网络有3个细节
- 3x3的卷积过后通常会接一个通道数更低的1x1的卷积,降低计算量,提升模型的非线性能力
- 除了最后一层使用线性激活函数外,其余层的激活函数Leaky ReLU(ReLU没有负数的导数,activate均值为正,导致bias shift)
- 训练中使用了Dropout与数据增强的方法来防止过拟合
- 特征提取网络有3个细节
特征图的意义
其精髓在于7x7x30的feature map。- 将原图划分为7x7个区域,每个区域就对应着最后特征图上的一个点。
如果一个物体的中心点落在某个7x7的区域中,那么那个区域就负责检测该物体。具体的,我们希望提取的那个点的feature可以预测B个bounding box以及bbox的置信度confidence score。
所谓置信包含两个方面,一是$Pr(object)$这个边界框包含目标的可能性大小,二是这个边界框的准确度(预测框与GT的IoU, $\text{IoU}^{truth}_{pred}$ )。所以置信度c定义为:$Pr(object) * \text{IoU}^{truth}_{pred}$
所以需要对应feature maps上的点的channel等于 $B*|x,y,w,h,c|+C$。v1中B=2,C=20,所以最后生成的feature maps通道数为30。
具体的实现上,前20个是类别概率值,中间两个是bbox的置信度,最后8个是两个预测框的x,y,w,h。纯粹是为了计算 切片方便。
- 损失计算
- 区分开正负样本:
- 当一个真实物体的中心落在了某个区域内,该区域就负责检测该物体。具体做法是将与该真实物体有最大IoU的bbox设为正样本,这个区域的类别真值为该真实物体的类别,该边框的置信度为1
- 除了上述被赋予正样本的bbox,其余bbox皆为负样本,负样本没有类别损失与边框位置损失,只有置信度损失,其真值为0
- Loss由5部分组成,均采用MSE损失:
$$\lambda_{coord}\sum_{i=0}^{s^2}\sum_{j=0}^B\mathbb{1}^{\text{obj}}_{ij}[(x_i-\hat{x_i})^2+(y_i-\hat{y_i})^2]\\
- \lambda_{coord}\sum_{i=0}^{s^2}\sum_{j=0}^B\mathbb{1}^{\text{obj}}_{ij}[(\sqrt{w_i}-\sqrt{\hat{w_i}})^2 + (\sqrt{h_i}-\sqrt{\hat{h_i}})^2] \\
- \sum_{i=0}^{s^2}\sum_{j=0}^B\mathbb{1}^{\text{obj}}_{ij}(C_i-\hat{C_i})^2 \\
- \lambda_{no\ obj}\sum_{i=0}^{s^2}\sum_{j=0}^B\mathbb{1}^{\text{no\ obj}}_{ij}(C_i-\hat{C_i})^2 \\
- \sum_{i=0}^{S^2}\mathbb{1}^{\text{obj}}_i\sum_{c\in \text{classes}}(p_i(c)-\hat{p_i}(c))^2
$$
- 区分开正负样本:
其中第一项是边界框中心坐标的误差项,$\mathbb{1}^{\text{obj}}_{ij}$是指第i个单元格存在目标,且该单元格的第j个bbox负载预测该目标。
第二项是bbox的宽高的误差项,通过平方差,降低对尺度的铭感,强化小物体的损失权重
第三项是包含目标的边界框的置信度误差项。
第四项是不包含目标的bbox的置信度误差项。$\lambda_{no\ obj}=0.5$调低负样本置信度损失的权重。
第五项是包含目标的单元格的分类误差项。$\mathbb{1}^{\text{obj}}_i$指的是第i个单元格存在目标。这里的C_i=$Pr(object) * \text{IoU}^{truth}_{pred}$
推理的时候需要NMS7x7x2=98个框,需要按类别NMS。
- 不足之处:
- 每个区域只有两个框,且两个框都指向同一个类别。这个限制会导致模型对小物体,以及靠的特别近的物体检测效果不好
- 由于没有anchor这类先验框,模型对新的,或者不常见宽高比例的物体检测效果不好,另外由于下采样率较大,边框的检测精度不高
- 损失函数中,大物体的位置损失权重越小物体的位置损失权重是一样的,导致同等比例的位置误差,大物体的损失会比小物体大,小物体的损失在总损失中占比较小,会带来物体定位的不准确。
YOLOv2
-
对于每一层的输入都做了归一化。提升2%mAP.
High resolution classifer高分辨率图像分类器
采用224x224 ImageNet图像进行分类模型预训练160 epoch,再采用448x448的高分辨率样本对分类模型进行finetune(10个epoch),使得网络特征逐渐适应448x448的分辨率,缓解了分辨率突然切换造成的影响。
Convolution with anchor boxes使用先验框
学习FasterRCNN预测anchor box的偏移量。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,因为anchor bbox的大小都不同,所以不能再使用MLP,8将全连接层和最后一个pooling层去掉*
将输入图片尺寸从448改为416,这样经过32倍downsample,可以得到13x13的feature map,使得特征图只有一个center cell(如果是偶数就会有四个)。
- 为什么希望只有一个center cell? - 因为大的object一般会占据图像中心,所以希望用一个center cell去预测。最后recall提升7%,mAP只下降0.3%
Dimension clusters 聚类提取先验框的尺度信息
通过Training GT的bbox的k-means聚类分析,自动寻找尽可能匹配样本的anchor box尺寸。传统欧式距离在bbox尺寸较大的时候误差也更大,而我们希望误差和bbox的尺寸没有太大关系,所以通过IoU定了如下距离函数:
其中centroid是聚类是被选中作为中心的边框,box是其他的边框,于是IoU越大,两者越接近。
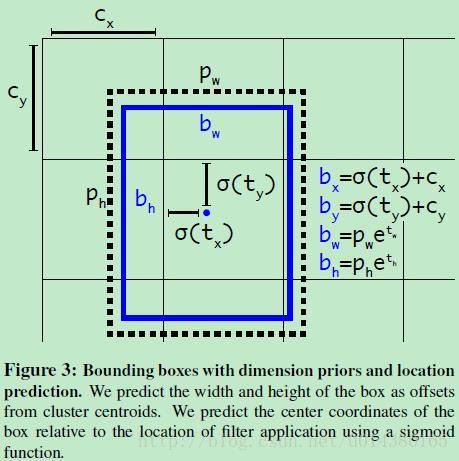
Direct Location prediction 约束预测边框的位置
借鉴于Faster RCNN的先验框方法,其位置预测公式:由于没有RPN网络去直接学习预测位移,所以在YOLO中直接取学习$t_x,t_y$,导致他们的取值没有任何约束,因此预测边框的中心可能出现在任何位置,训练早期阶段不容易稳定。YOLOv2调整了预测公式,将预测边框的中心约束在特定的grid网格内:
其中,
- $b_x,b_y,b_w,b_h$是预测边框的中心和宽高。
- $Pr(object)*IoU(b,object)$是预测边框的置信度,这里对预测参数$t_o$进行sigmoid变换后作为置信度的值。
- $c_x,c_y$是当前网格的左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1.
- $p_w,p_h$是先验框的宽高。
- $\sigma$是sigmoid函数。
- $t_x,t_y,t_h,t_w,t_o$是要学习的参数。
因为使用了限制让数值变得参数化,也让网络更容易学习,更稳定。
Fine-Grained Features(passthrough层检测细颗粒度特征)
图像中的对象会有大有小,输入图像经过多层网络特征提取,最后输出的feature map中较小的对象可能并不明显甚至被忽略掉了。于是引入了passthrough层:在最后一个pooling层之前,特征图大小为26x26x512,将其1拆4,让他们和经过pooling,conv后的feature map 13x13x1024直接concat,得到13x13x3072.
Multi-Scale Training 多尺度图像训练
每10个batch,网络会随机选择一个新的图片尺寸,[320,608,32],希望网络在不同的输入尺寸上都达到一个很好的预测效果。Hierarchical classification分层分类
提出了一种在分类数据集和检测数据集上联合训练的机制:object detection的数据集取训练detection,classification的数据集只训练分类loss。
但是ImageNet有9000个种类,coco只有80种,作者使用multi-label模型,即假定一张图片可以有多个label,且不要求label间独立。采用以下策略重建了一个树形结构:
- 遍历ImageNet的label,然后在WordNet中寻找该label到根节点的路径
- 如果路径只有一条,那么就将该路径直接加入到分层数结构中
- 否则,从所有路径中选择最短的一条加入到分层树中。
这个分层树就称之为WordTree,作用在于将两种数据集按照层级进行结合。
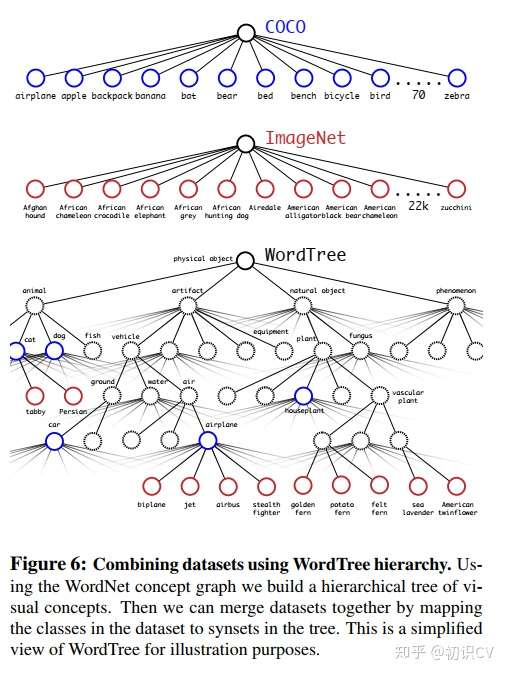
分类时的概率计算借用了决策树思想,某个节点的概率值等于该节点到根节点的所有条件概率之积。最终结果是一颗 WordTree (视觉名词组成的层次结构模型)。用WordTree执行分类时,预测每个节点的条件概率。如果想求得特定节点的绝对概率,只需要沿着路径做连续乘积。
YOLOv3
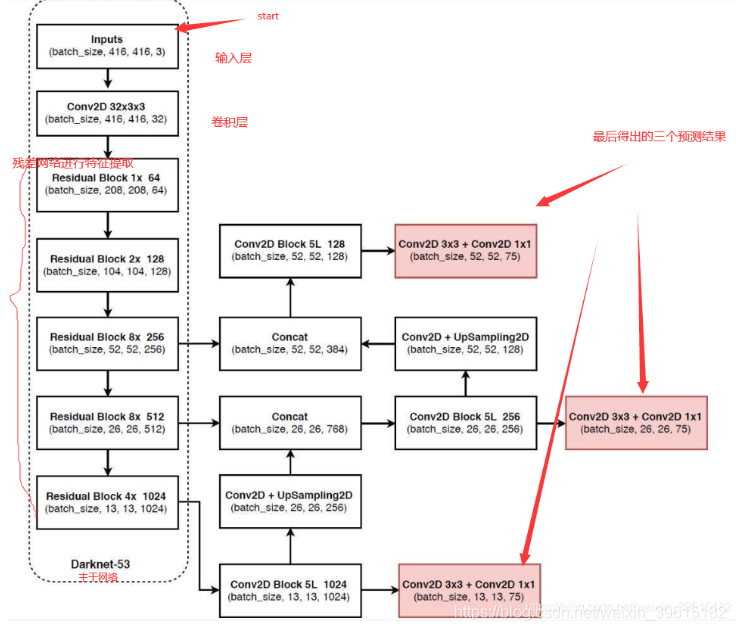
从特征获取预测结果
多特征层进行目标提取,一共提取三个特征层,三个特征层位于darknet53的不同位置,分别位于中间层,中下层,底层,三个特征层的shape分别为(52,52,256),(26,26,512),(13,13,1024),这三个特征层后面用于与上采样后的其他特征层concat
第三个特征层(13,13,1024)进行5次卷积处理(提取特征),处理完后一部分过卷积并上采样,另一部分用于输出该尺寸下的预测结果(13,13,75)。Conv2d 3x3 和Conv2d 1x1起到通道调整的作用,调整成输出需要的大小。
上一步中上采样后得到(26,26,256)的特征层,然后与Darknet53网络中的特征层(26,26,512)进行Concat,得到的shape为(26,26,768),再进行5次卷积。同样一部分过卷积并上采样,另一部分用于输出对应的预测结果(26,26,75)。Conv2d 3x3 1x1同上。
重复上一步,将上采样的特征与(52,52,256)的特征Concat,再次5次卷积得到shape为(52,52,128),并过Conv2d 3x3 1x1得到(52,52,75)
- 如果物体在图中较大就用13x13检测,较小就用52x52来检测。
预测结果的解码
和V2一样