动机
无论是简单的FNN,还是CNN,异或是GAN,似乎都只关心一次性的输入数据,有什么办法能处理一串数据么?
或者说有什么办法能够利用之前学习到的知识,作用在之后的学习上么?
类型
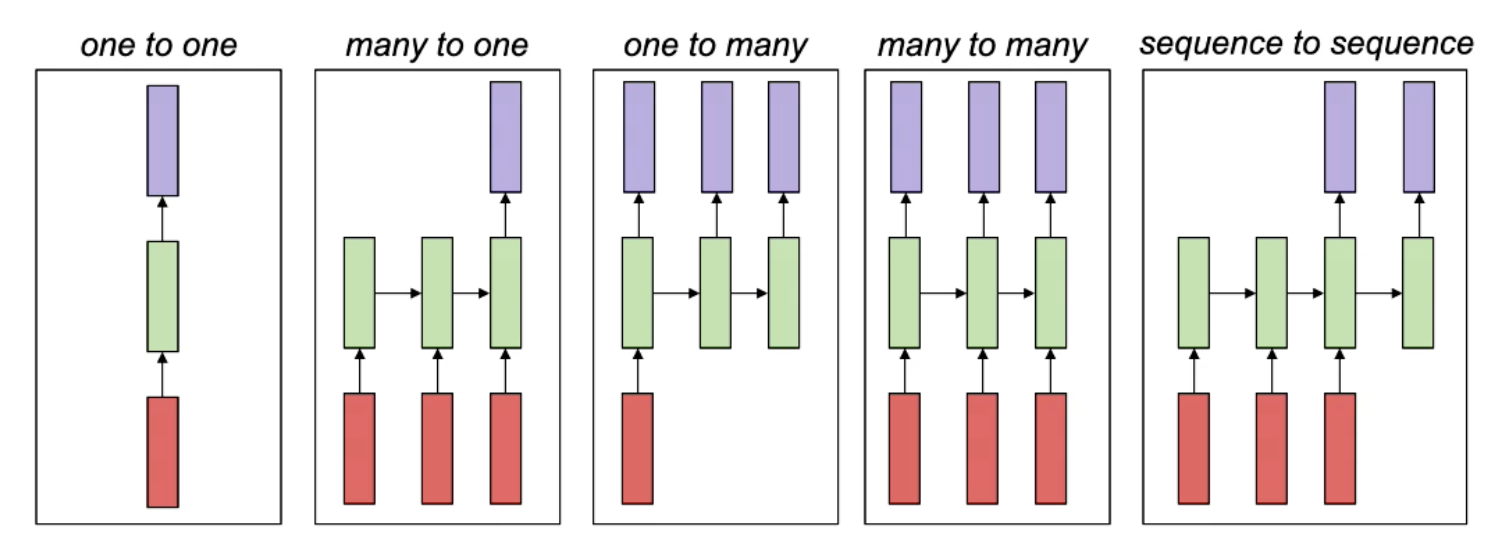
- many-to-one:
- 可以用于语音识别(声纹作为sequential input,而识别的单词就是一个output)
- 情感划分:判断一句话是积极还是消极的
- 视频分类:从一连串的画面判断并分类
- one-to-many:
- 音乐合成:输入一个类别,生成符合类别的音乐
- 文章生成:同上
- 图像理解:输入图片,理解各个之间的关系,生成语句来描述这张图片
- many-to-many(同等长度):
- 持续的情感预测:从一段视频中判断情感变化
- 语音增强:消除意外的不必要的杂音
- 视频分类:每一帧的角度
- sequence-to-sequence(不同长度):
- 机器翻译
- 回答问题
以上这些都可以用循环神经网络实现
Simple RNN
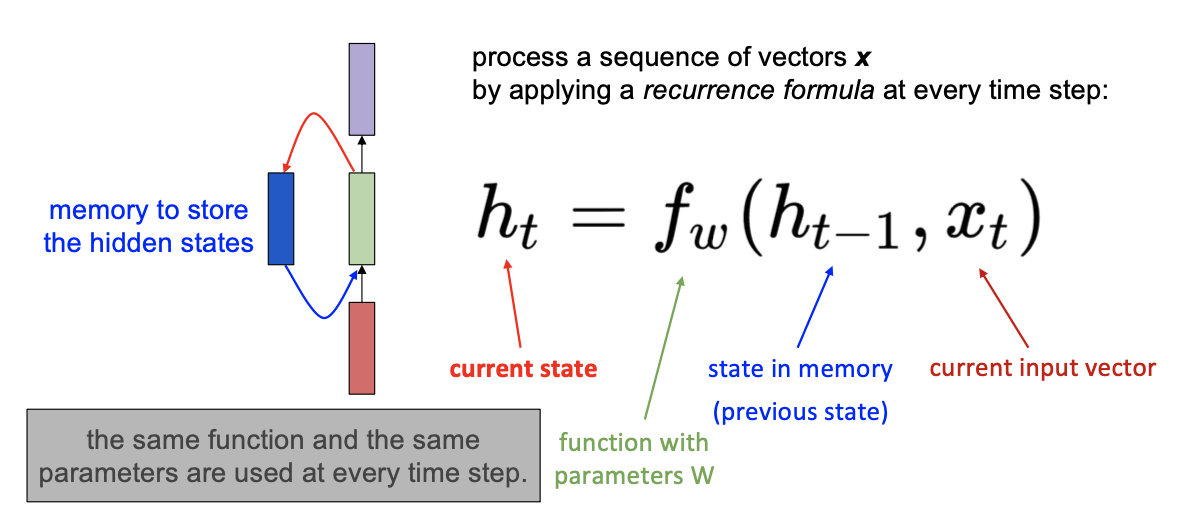
每一步的state $h_t$ 都受到前一步的state $h_{t-1}$ 与当前这一步的输入 $x_t$ 值影响
其中 $f_w$ 映射了参数w和两个输入值的关系,也即:
而最后的输出值
梯度爆炸和梯度消失
当我们又一个很长的输入时,向前传播没什么问题,但是当我们计算了loss后,试图将梯度向后传递时,问题就出现了。
对t时刻,隐状态向量 $h_t$ 的偏导数是
那么对于最早的 $h_0$ 的偏导数就是
而 $\frac{\partial h_t}{\partial h_0}$ 展开就是:
这也就是说我们在反向传播的过程中需要反复乘以$W_{hh}$,对其进行奇异值分解SVD,得到
那么最后:
也就是说如果输入长度是n,我们就需要对 $\sigma$ 求n次幂。那么就很容导致梯度爆照($\sigma \gt 1$),或者梯度消失($\sigma \lt 1$)
- 梯度爆炸:
- 会导致网络不收敛,影响训练。
- 解决方法:梯度裁剪,即设定一个阈值,超过就把梯度设定为那个阈值
- 梯度消失:
- 会导致捕捉长距离依赖的能力下降。比如我在开头说了一个词,过了足够长的时间,在结尾就会被遗忘。
- 解决方案:LSTM,GRU通过门机制来控制RNN中信息流动来缓解梯度消失,也就是有选择性的遗忘或记得某些信息
LSTM
长短期记忆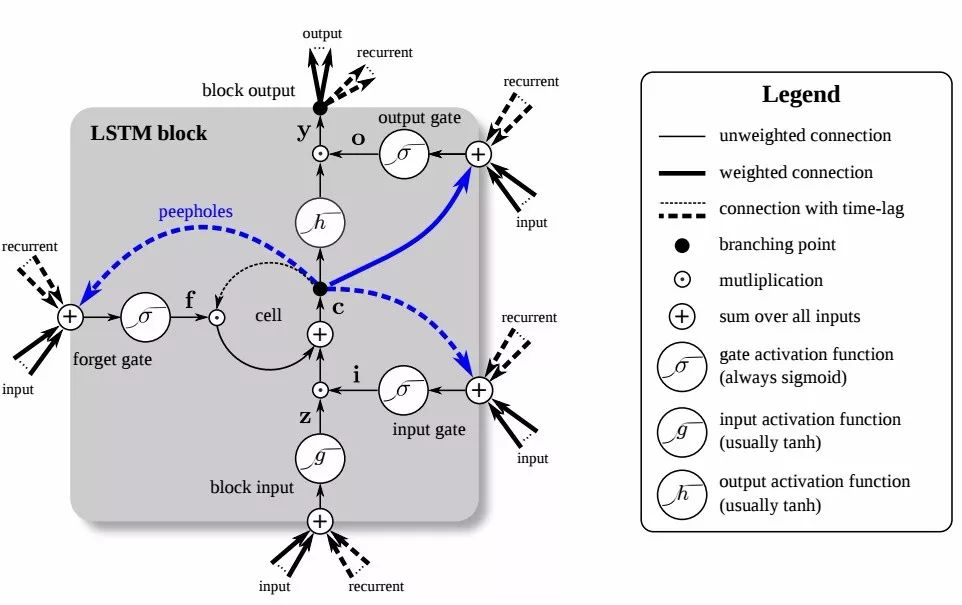
O输出门:控制那些 $h_{t-1}$ 可以被传输到下一个时刻
I输入门:控制当前词 $x_t$ 的信息融入到细胞状态 $c_t$,判断当前词 $x_t$ 对全局的重要性
F遗忘门:控制上一个时刻的细胞状态 $c_{t-1}$ 的信息融入细胞状态 $c_t$。
- 在理解一句话的时候,当前词 $x_t$ 可能继续延续上文的意思去描述,
- 也可能从当前词 $x_t$ 开始重新描述新的内容,与上文无关。
- 与输入门I相反,F不对当前词 $x_t$ 的重要性进行判断,而判断的是上一时刻的细胞状态 $c_{t-1}$ 对当前计算的细胞状态 $c_t$ 的重要性
C细胞状态:综合了当前词x_t和前一时刻细胞状态c_(t-1)。
- 通过从 $c_{t-1}$ 到 $c_t$ 的「短路连接」,梯度得已有效地反向传播。
- 当 $f_t$ 处于闭合状态时,$c_t$ 的梯度可以直接沿着最下面这条短路线传递到 $c_(t-1)$ ,不受参数 $W_{xh}$ 和 $W_{hh}$ 的影响,这是 LSTM 能有效地缓解梯度消失现象的关键所在。
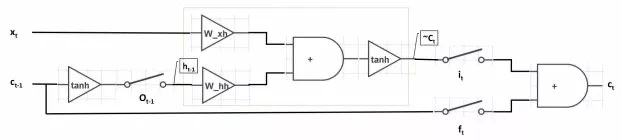
降维理解
简化 $i_t$, $f_t$, $o_t$的输入,降维为一维( $\odot$ 在一维中就是相乘),简化单元为二值输出作为开关。
所以如果 $i_t=1$(开关闭合)、$f_t=0$(开关打开)、$o_t=1$(开关闭合)时,LSTM 退化为标准的 RNN。
Extension: Peephole Connections
简单来说就是把细胞状态放在门里,让门去选择是否使用。
Extension: combine forget and input gates
联合决定是加入还是忘记
GRU
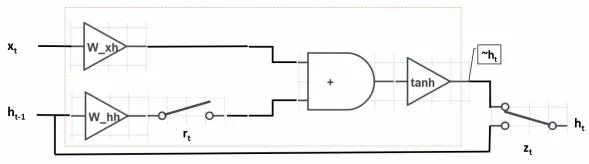
R重置门:用于控制前一时刻的隐藏单元 $h_{t-1}$ 对当前词 $x_t$ 的影响。如果 $h_{t-1}$ 对 $x_t$ 不重要,即从当前词 $x_t$开始表述新的意思,与上文无关了。
Z更新门:$z_t$ 用于决定是否忽略当前词 $x_t$。类似于LSTM中的输入们 $i_t$ 。$z_t$可以判断当前词 $x_t$ 对整体意思的表达是否重要。 当 $z_t$ 开关接通下面的支路时,我们将忽略当前词 $x_t$ ,同时构成了从 $h_{t-1}$ 到 $h_t$ 的短路连接,这使得梯度得以有效反向传播。和LSTM相同,这种短路机制有效的缓解了梯度消失的现象,和highway network十分相似。
CTC
- [More to be filled]